
What is ChatGPT and why is it so successful?
We’ve all experienced the craze known as “ChatGPT”. It feels like we can ask it anything, and it will return an informative, conversational, and eerily human-like response. If we think back to the Turing Test, proposed in the 1950s to test whether machines can think like humans, there’s not doubt that ChatGPT will pass it with flying colors!

So what exactly is ChatGPT and what makes it so successful? It seems like it came from a serendipitous combination of several advances:
- Transformers as a new attention-based neural network model proposed in 2017
- OpenAI and its development of the GPT-3
- Reinforcement Learning from Human Feedback (RLHF) added to fine-tune GPT-3 into ChatGPT
Transformers
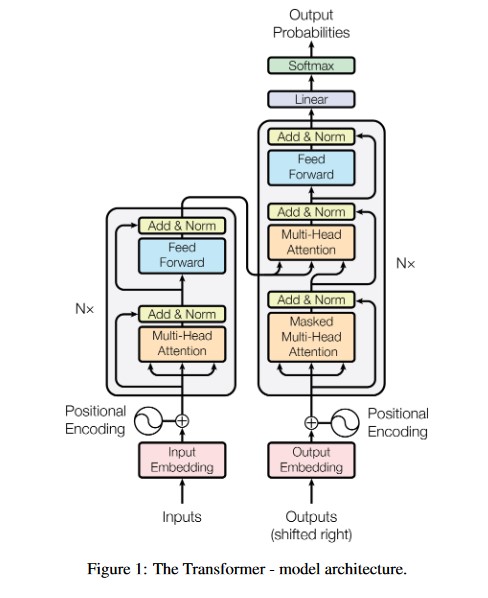
Proposed in 2017 in this paper, transformers were a new network architecture, based “solely on attention mechanisms, dispensing with recurrence and convolutions entirely”. This was significant as at that point the state-of-the-art (SOTA) approaches in language and computer vision modeling were mainly dominated by recurrent and convolutional neural networks (RNNs and CNNs) respectively. In particular, the ability of transformers to use ‘self-attention’ only, allowing distant elements to influence each other to compute inputs and outputs. This allows a more ‘human-like’ processing of words and meaning, and with computational advantages as well over RNNs and CNNs, it is no wonder that they were heavily regarded as a ‘foundational model’ in this paper.
OpenAI
First announced as a non-profit in 2015 by giants such as Elon Musk and AWS, the company quickly stole the headlines when they trained bots for the complex MOBA game Dota 2 that requires coordination and teamwork between a 5-player team, and they rented 128,000 CPUs and 256 GPUs from Google for multiple weeks. The strong focus in reinforcement learning and crazy amount of compute used for the feat was impressive to many people. After transition to for-profit, with its 1 billion dollar investment it produced the Generative Pre-trained Transformer 3 (GPT-3), a language model trained on large internet datasets and capable of using natural language to answer questions. This was the first commercial product it produced, and that was only in 2020. So how did this lead to ChatGPT?
Reinforcement Learning from Human Feedback (RLHF)
| What Stable Diffusion thinks of RLHF |
The secret sauce that led to the fine-tuned ChatGPT system seems to be RLHF. In reinforcement learning, a reward function guides the agent’s learning as it tries to take actions to maximize reward. In RLHF, this ‘reward model’ is actually trained directly with human feedback, where the agent’s responses were ranked by humans and then used to score ouputs similar to an Elo rating system. Using a ranking system to generate a scalar reward for the model instead of directly applying scalar values allows much more regularizable data (see this article from huggingface for a wonderful breakdown). This human component is why ChatGPT is so easy to talk to - its responses have been fine-tuned with human input to be the most understandable and meaningful.
So what’s next for us after being replaced by ChatGPT?
The question that has been on everyone’s minds since the release of this amazing technology. Will we all be replaced by ChatGPT? OpenAI themselves wrote a paper suggesting that the US workforce may have around 10-50% of their tasks impacted! In other words, as long as a job has tasks that ChatGPT can make more efficient, it is likely that those functions will be replaced. If you imagine a scenario where a cashier did not have a calculator to do their job (pre-1778s apparently), obviously the efficiency and even the requirements of the job would have been quite different. Of course, there are several limitations that this kind of ‘exposure analysis’, including but not limited to:
- breaking down jobs into a ‘task-based framework’
- inaccuracy and lack of domain-expertise in task-labelling
- expectations of LLMs to grow at a similarly rapid pace
- necessary human aspects of certain jobs/tasks
Needless to say, we should all start paying more attention to these language models. They could really end up changing our lives considerably, perhaps not unlike the introduction of PCs into our daily home and work lives!